
AWS S3 Files: Accelerating Agentic AI with Native File Access
For the tech corridors of Seattle, Washington, the announcement that Amazon is bridging the gap between object storage and native file systems isn’t just another cloud update—it’s a fundamental shift in how the city’s massive AI workforce will operate. From the sleek offices in South Lake Union to the engineering hubs near the University of Washington, developers have long wrestled with the “object-file split.” When your data lives in Amazon S3 but your AI agents—like Claude Code or Kiro—suppose in terms of local directories and file paths, you end up with a fragmented workflow. Until now, that meant tedious manual downloads or relying on FUSE-based drivers that often felt like a fragile workaround. The introduction of S3 Files effectively turns a massive cloud bucket into a local hard drive, removing the friction that has slowed down agentic AI pipelines across the Pacific Northwest.
The Technical Friction: Why Object Storage Broke the AI Workflow
To understand why S3 Files is a breakthrough, one has to understand the inherent conflict between how humans (and AI agents) organize data and how the cloud stores it. S3 was designed for durability and scale, utilizing API calls to retrieve “objects.” However, AI agents are built to navigate directories, read file paths and execute local scripts. As Andy Warfield, VP and distinguished engineer at AWS, pointed out, S3 simply isn’t a file system. it lacks the ability to perform atomic moves and doesn’t actually have directories in the traditional sense.
In the past, developers tried to solve this using FUSE (Filesystems in USErspace) drivers, such as those used by Google Cloud Storage or Azure Blob NFS. Whereas these tools “faked” a file system, they often created a “data shuffle” where metadata would get out of sync or certain file operations were flatly refused. For a developer in Seattle building a multi-agent pipeline, this meant that as an agent’s context window compacted, the session state—and the record of what had been downloaded locally—would vanish. The agent would literally “forget” where its data was, forcing the human operator to constantly remind the AI that the data was available locally.
The EFS Integration: Moving Beyond the Workaround
S3 Files departs from the FUSE model by connecting AWS’s Elastic File System (EFS) technology directly to S3. This creates a native file system layer where the data remains in S3, but the agent sees it as a local environment. This architecture allows for simultaneous access; thousands of compute resources can connect to a single S3 file system, with aggregate read throughput potentially reaching multiple terabytes per second. This is a critical leap for the “agentic AI” era, where multiple agents might need to read and write to shared project directories or log investigation notes in real-time without the risk of stale metadata.
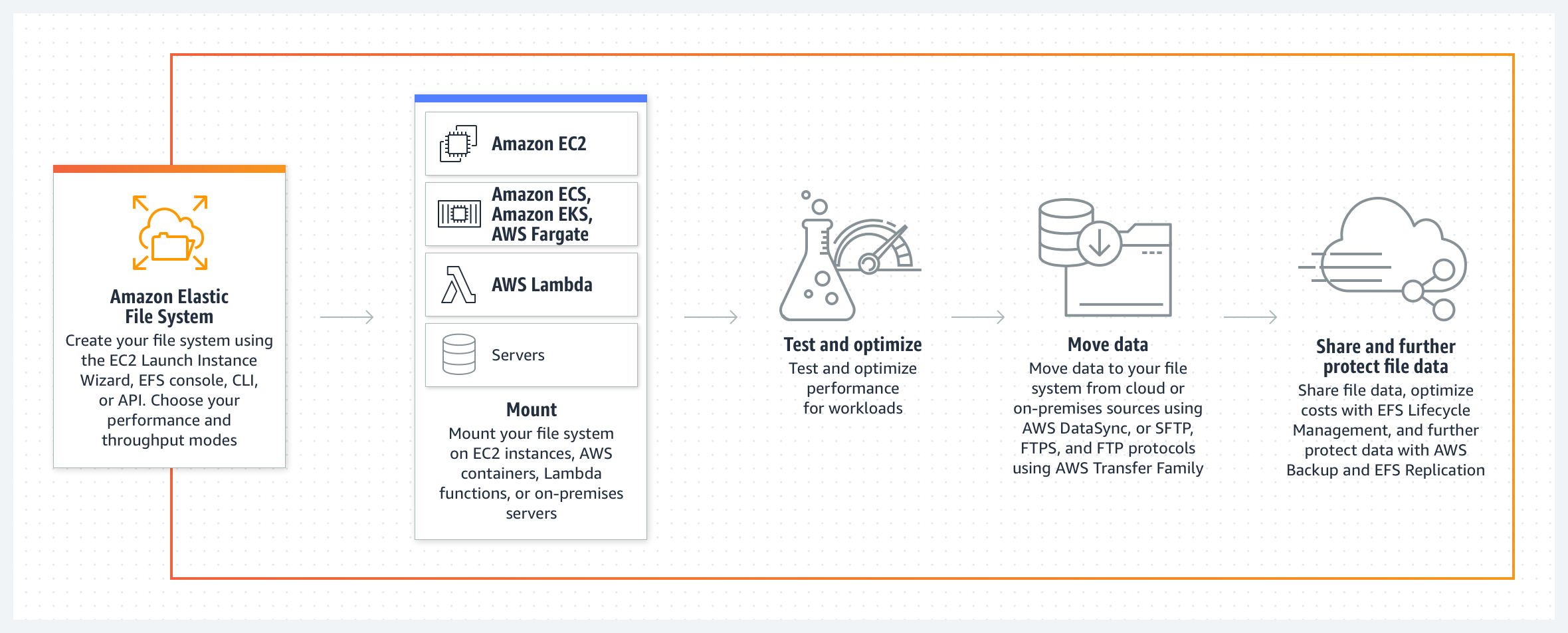
for those implementing Retrieval-Augmented Generation (RAG) pipelines, this integrates seamlessly with S3 Vectors, which launched in December 2024. While S3 Files handles the operational workspace, S3 Vectors provides the similarity search capabilities necessary for intelligent tool selection and retrieval, creating a comprehensive ecosystem for autonomous AI operations.
The Macro Impact on Enterprise AI Architecture
Industry analysts are viewing this as more than just a feature update. Jeff Vogel of Gartner notes that S3 Files eliminates the need for a separate file system layer, turning the file system into a “view” rather than a separate dataset. This removes an entire class of failure modes—specifically those unexplained training or inference failures caused by metadata discrepancies that are notoriously difficult to debug. Dave McCarthy from IDC describes this as the “missing link,” allowing an AI agent to treat an exabyte-scale bucket as its own local hard drive.
For enterprises, the shift is concrete: S3 is no longer just the destination where an agent dumps its final output; it is now the environment where the actual perform happens. This convergence reduces the need for complex sync pipelines and duplicated data, allowing teams to focus on optimizing data management and agent logic rather than infrastructure plumbing.
Navigating the Local AI Infrastructure Landscape in Seattle
Given my background as an Executive Geo-Journalist and Lead Pundit, I’ve seen how global cloud shifts manifest in local professional needs. If your organization in the Seattle area is transitioning to agentic AI workflows using S3 Files, you aren’t just looking for a general IT person. You need specialists who understand the intersection of cloud architecture and autonomous agent orchestration. To successfully implement these tools, look for these three types of local experts:
- Cloud Infrastructure Architects (AWS Specialized)
- Look for professionals with deep experience in Elastic File System (EFS) and S3 bucket policy orchestration. They should be able to demonstrate how to mount S3 buckets into local environments without compromising security or incurring unnecessary latency. Prioritize those who have specifically worked with the AWS re:Invent 2024/2025 feature sets.
- AI Orchestration Engineers
- These are the experts who can build the actual “pipelines” using tools like LangGraph or Amazon Bedrock. You need someone who understands how to manage agent session states and context windows, ensuring that the modern S3 Files native access is leveraged to prevent the “memory loss” issues common in earlier agentic iterations.
- Enterprise Data Governance Consultants
- Because S3 Files allows thousands of resources to access the same data simultaneously, the risk of “data sprawl” increases. Seek consultants who specialize in IAM (Identity and Access Management) and data lifecycle policies to ensure that your autonomous agents aren’t inadvertently modifying critical system-of-record data in your S3 buckets.
Ready to discover trusted professionals? Browse our complete directory of top-rated data experts in the Seattle area today.